原创 吴 炅等 南京林业大学学报


专题报道
结合树冠体积的油茶树高与产量估测研究
吴 炅1,蒋馥根1,彭邵锋2,马开森1,陈 松1,孙 华1,2
1.中南林业科技大学林业遥感信息工程研究中心;2.湖南省林业科学院。

油茶(Camellia oleifera)作为我国特有的食用油料木本植物,其种子可用来榨取食用油,具有较高的食用和医药价值。近年来我国油茶产业取得了一定的发展,但油茶总产量一直处于较低水平,随着人们对食用油用量的不断增加,茶油的生产难以满足市场需求,因此科学管理油茶,并对油茶产量进行准确估测具有重要意义。树高作为林木的垂直结构特征,是评估作物生长的一项指标,对作物产量估测具有参考价值,精准地获取油茶树高有益于产量估测。
传统的油茶树高和产量调查主要以实地采摘鲜果为主,恶劣的环境和天气常给调查带来不便。遥感技术已被用于大规模的森林调查,由于光学变量在一定程度上能反映作物生长状况,利用光学变量估测作物株高和产量已经成为常用的方法。然而光学遥感通常忽视了树木的垂直结构和三维结构信息,容易造成光谱信息过饱和,三维激光扫描技术可全面地获取树冠点云数据,实现树木三维结构参数的自动探测,且获取的林木因子精度理想,但激光扫描仪器价格昂贵,获取的数据量庞大。无人机摄影测量技术可快速地获取高分辨率林木影像,经过密集匹配后生成的点云带有空间坐标,可进行单木的三维结构分析。相比传统的实地调查,无人机具有方便、快捷等优势,能同时获取多维的结构信息,相比地面三维激光扫描技术,无人机更适用于作业调查,其密集匹配点云的数据量可观,便于后续处理。因此通过无人机同时获取光学变量和高度变量建立估测模型,可为树高和产量的估测提供更有效的方式。
树冠体积可直接反映树木生长活力,同时也是研究三维绿量和经济林估测产量的重要指标。然而,树冠具有复杂的空间结构,且表现为外形不一,导致表征树冠特征的树冠体积测量复杂,难以获取真实值。树冠的三维数字化可以通过三维分析模拟数字表面,呈现出更直接的树冠空间信息,利用离散的点云展现树木三维信息已经成为一种主流方式。然而基于点云数据对单木树冠重建具有挑战性,如何高效﹑精确地模拟树冠轮廓也是待解决的研究问题。空间插值通过采样点的测量值对整个区域进行预测,是实现空间点数据转化为面状数据的有效手段。将树冠点云作为采样点进行空间插值,并将插值栅格转化为不规则三角网(TIN)能够还原树冠的原始轮廓,精确地记录树冠的三维信息,相比分段计算树冠体积的方式,具有快速且高效的优点。过滤三角网可有效剔除树冠外部间隙,使树冠拟合接近真实轮廓,然而不同插值方法因研究目的不同会产生相异的插值结果,寻找获取表面信息的最优插值方法有助于树冠体积和产量的估算。本期论文推荐的作者以无人机正射影像及影像密集匹配生成的点云为数据源,利用克里金法(Kriging)、反距离权重法(inverse distance weight, IDW)、自然邻近点法(natural neighbor,NN)和过滤三角网法(filteringtriangulation, FT)模拟树冠表面,分析不同插值对树冠体积获取的影响,确定适用于体积计算的最优方法,结合树冠体积通过多元线性回归、随机森林、K最邻近法建立油茶树高和产量估测模型并进行对比分析,以期为油荼树高和产量的估测提供高效的技术手段。
下面跟学报君一探究竟!
作者简介
通讯作者

孙华,男,1979年9月出生,湖南隆回人,博士,教授,硕士生导师,主要研究领域为林业定量遥感,激光雷达林业应用,数字化森林资源监测。
第一作者

吴炅,女,1998年5月出生,中南林业科技大学硕士研究生。

关键词:经济林;油茶产量;随机森林;无人机;树冠体积;空间插值
基金项目:湖南省林业科技创新专项(XIK201986);国家重点研发计划(2016YFDO702105);湖南省普通高校青年骨干教师培养对象项目(7070220190001)。
引文格式:吴灵,蒋馥根,彭邵锋,等.结合树冠体积的油茶树高与产量估测研究[J].南京林业大学学报(自然科学版), 2022,46(2):53-62.WU J,JIANG F G,PENG S F,et al.Estimating the tree height and yield of Camellia oleifera by combining crown volume[J].Jourmal of Nanjing Forestry University (Natural Sciences Edition) ,2022,46(2):53-62.DOI:10.12302/j. issn.1000-2006.202108051.

1目的
以长沙县明月村油茶林基地为研究区,探讨利用无人机倾斜摄影提取树冠体积进行油茶树高和产量估测的可行性。
2方法
基于无人机正射影像和密集匹配点云,提取波段反射率、植被指数、纹理因子.高度特征等遥感变量和冠幅等冠层参数,同时利用克里金法、反距离权重法、自然邻近点法和过滤三角网法分别获取油茶树冠体积,建立多元线性回归、随机森林,K最邻近模型估测油茶树高和产量,并以地面三维激光点云获取的树冠体积、样地实测树高和产量作为实测值分别对估测结果进行精度评价。
2.1 试验材料
实验区位于湖南省长沙县东北部的油茶研究基地内(112°56'~113°30'E,27°55’~28°40'N),属于平原地区,年均降水量在1389.8 mm左右,森林覆盖率为75%。该区受季风影响,季节变化明显,1月平均气温在0 ℃以上,土壤疏松呈酸性,适宜油茶等经济林木的生长。
2.2 研究方法
2.2.1 样地数据
数据采集时间为2019年11月和2020年11月,在研究区内选取85株生长健康的油茶树,利用水准尺直接测量油茶树的高度作为实测树高,取得果实袋装称重,记录每株油茶的鲜果质量作为实测产量,树高、产量的平均值分别为2.5 m、7.1 kg,最小值分别为1.8 m、1.4 kg,最大值分别为3.4 m、13.4 kg ,标准差分别为0.3 m、2.8 kg。
2.2.2 三维激光点云数据
利用三维激光扫描仪FARO Focus 3D X330,辅以配套的参考球对油茶林进行扫描。单株油茶周围布设3个测站,3~5株油茶周围布设5个测站,利用伸缩杆调整参考球高度,扫描过程需保证参考球无遮挡。设置扫描范围水平方向为360° ,分辨率为1/4,在该分辨率下的平均单站扫描时间为11 min。在FARO Scene中完成坐标点匹配,形成三维立体点云,并剔除主干点云和树冠点云存在的噪点。为了便于后续树冠体积的计算,将树冠点云坐标进行平移处理,保证所有点云的坐标处于第一象限。
2.2.3 无人机点云数据
设置无人机航速为36 km/h,旁向重叠率为75% ,在实验区上空90 m高度拍摄油茶林地,共获取试验区3个可见光波段红(band1)、绿( band1) 、蓝(band3)下的138幅影像。将无人机影像导入Pix4Dmapper软件,快速完成相邻航片之间的拼接和校正,生成测区 2 cm分辨率的数字正射影像(DOM)和密集匹配点云。通过改进的渐进加密三角网滤波(IPTD)算法分离点云中的地面点和非地面点,分别插值生成5 cm分辨率的数字高程模型(DEM)和数字表面模型(DSM),两者作差可得冠层高度模型(CHM),将CHM用于后续变量提取,无人机点云通过插值获取的DEM 、 DSM、CHM模型见图1。

▲图 1 由无人机点云获取的DEM、 DSM 和CHM
2.3 单木分割及树冠体积提取
采用多尺度标记优化分水岭方法分割油茶单木树冠。该方法首先利用面向对象的方式分析DOM影像特征,分离油茶林地与非林地对象,对保留的油茶对象做整合处理,消除碎多边形。然后以半径为3个像素的圆形元素,对分离的油茶林地对象进行形态学腐蚀运算,通过基于像素的形态学腐蚀将相连的树冠对象分离,得到油茶的树顶标记,并利用区域增长算法对树顶标记做迭代处理,遍历标记的邻域像元,以区域增长后的树冠标记修正油茶林地。最后以修正后的油茶林地为基础,通过分水岭方法分离油茶树冠,得到实验区单株油茶对象,并依据油茶对象的分割边界提取单木树冠点云。
为了对比克里金法(Kriging)、反距离权重法(IDW)、自然邻近点法(NN)和过滤三角网法(FT)4种插值方法获取的树冠体积V,以单株油茶树冠点云为单位,一方面分别采用克里金法、反距离权重法和自然邻近点法对点云进行插值分析,生成栅格数据,通过GIS的三维分析模块将栅格转化为TIN;另一方面,以树冠点云为单位,通过三维分析创建TIN,利用过滤三角网方法对TIN边界的三角形进行筛除,形成新的TIN。基于4种方法获取的TIN,以单木树冠边界作为约束,对边界和冠体点云的内插区做相交处理,确定两者公共区域,以x方向和y方向所形成的平面为水平面,将树冠点云最低点所在的水平面做为参考平面,通过三维分析计算参考平面上方公共区域的凸包体积,分析不同方法对计算树冠体积的影响,并选择最优结果作为特征变量参与建模。
2.4 基于无人机影像和密集点云的特征选取
基于正射影像,提取树冠对象的东西冠幅(CEW)、南北冠幅(CSN),计算两个主方向的冠幅均值作为平均冠幅(C) ,引入树冠体积(V)为生长因子变量。选择3个可见光单波段反射率、两波段和三波段比值形成的9个光谱变量,2个常用的图像指数包括过绿指数(IEXC)和植被颜色指数(ICIVE) 以及均值(TMean)、嫡(TEntropy)、同质性(THomogeneity)、异质性(TDissimilarity)、相关性(TCorrelation)、方差(TVariance)、角二矩阵(TSecond moment)、对比度(TContrast)8个纹理因子,总计22个特征变量用于建模。波段比值和图像指数的计算公式如下:
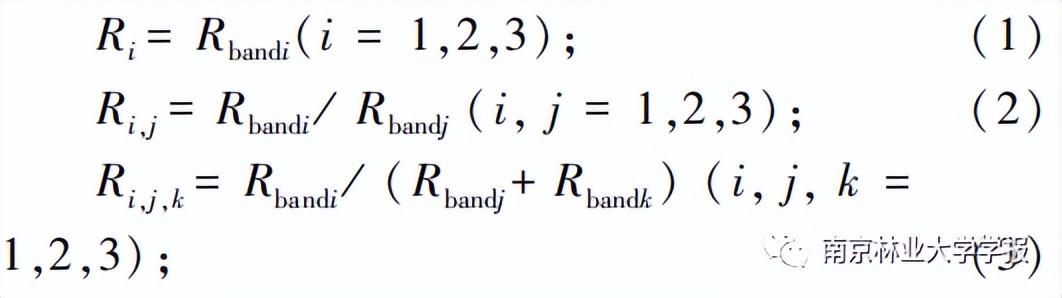

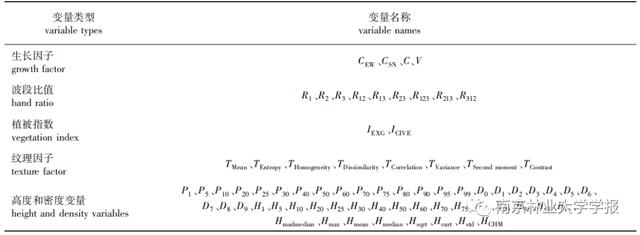
式中:Ri为单波段反射率、Rij、Ri,j,k分别为两波段和三波段比值;Rbandi、Rbandj和Rbandk分别表示无人机影像第ij和k波段的反射率。以油茶点云插值生成的冠层高度模型为底图,以树冠对象的边界为掩膜,提取树冠对象内的最大冠层高度值作为HCHM,选择15个高度百分位数(P1—P99),10个密度变量(D0—D9), 15个累积高度百分位数(H1—H99),8个高度变量(Hiq、Hmadmedian、Hmax、Hmean 、Hmedian 、Haqrt、Hcurt、Hstd),总计49个变量用于建模,表1为特征集构建结果。
▼表 1 特征集构建结果
2.5 结合树冠体积的油茶树高和产量估测模型构建
利用多元线性回归(multiple linear regression,MLR)、随机森林(random forest,RF )和K最邻近法(K-nearest neighbor, KNN)构建估测模型,并对估
测精度进行比较。
2.5.1 变量筛选
利用线性逐步回归和重要性评价法分别对变量进行筛选以分别构建线性和非线性模型,其中MLR通过线性逐步回归筛选变量,RF和KNN通过重要性评价获取最优变量组合。
计算各变量与估测变量之间的皮尔森(Pearson)相关系数,选择显著性水平在0.05以上的变量,结合方差膨胀因子(variance inflation factor, VIF)进行共线性分析,利用逐步回归筛选变量,基于保留的变量建立MLR模型。
通过RF先计算每棵决策树对应的袋外误差,对某一变量进行干扰,分析干扰前后误差衡量变量的重要性。依据重要性排序,逐步剔除重要性较低的变量进行建模,按照精度判断保留的变量个数,将保留变量组成新的特征集,根据新特征集再次进行重要性排序,重复以上步骤找到精度最优的变量组合:
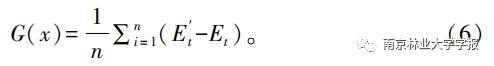
式中:G(x)表示变量x的重要性;n表示决策树数量;Et表示变量干扰前计算的袋外误差;E‘t表示变量干扰后计算的袋外误差。
2.5.2 建模过程
先利用提取的变量建立树高估测模型(HMLR,HRF,HKNN),将估测得到的树高作为新的特征H与其他变量共同建立估产模型(H-YMLR,H-YRF,H-YKNN),分别在树高估测模型和估产模型中引人树冠体积(V),得到新的估测模型,再结合实测树高(Hm)和其他变量建立估产模型,最后利用提取的变量建立估产模型。
2.6 体积提取与产量估测的精度评价
传统的树冠体积计算需要测量胸径、冠幅、树高等因子,先将树冠分层,再根据各层冠体的形状特征选择合适的几何模型计算体积,传统计算方式易受到树冠形态的影响。而体元模拟法用n个小立方体模拟树冠形状,树冠体积即为n个小立方体的体积之和,其优点是不受形态约束,当物体被分割的单元越小,分割越稳定,体元的体积越小,模拟的树冠体积越真实。为了评价树冠体积提取的准确性,将地面激光点云数据进行体元累加后的体积作为实测值,分析对比无人机点云通过不同插值方法提取体积的结果,并计算提取值与实测值之间的平均相对误差(σRE)作为评价指标,计算公式为:

式中:vi表示提取的树冠体积;Vi表示体积实测值。
采用决定系数(R2)、均方根误差(RMSE)和相对均方根误差(RRMSE)作为树高和产量估测的精度评价指标。
3结果
过滤三角网是获取油茶树冠体积最有效的方法,其平均相对误差(31.54%)优于反距离权重法(36.73%)、克里金法(37.04%)和自然邻近点法(38.54%)。将树冠体积作为特征变量参与建模后,树高和产量的多元线性回归、随机森林,K最邻近模型的精度均有所提升(树高相对均方根误差分别减小了3.77% ,0.78% ,0.64% ,产量相对均方根误差分别减小了1.32%,0.34%,0.16%)。对比3种估测模型,随机森林模型的决定系数均优于多元线性回归和K最邻近(树高决定系数分别为0.78,0.51和0.19,产量决定系数分别为0.61,0.48和0.24)。分别使用估测树高和实测树高参与产量建模的精度无明显差异。
3.1 油茶树冠单木分割及点云提取结果
油茶单木分割结果及点云重建结果见图2。分水岭分割正确识别的油茶株数为75,错误识别的株数为10,单木识别率为88.23%。高分辨率影像在进行分割时,通过标记分水岭方法能有效减少噪声的干扰,因此取得了较好的分割结果,对于未识别的单木采用解译的方式进行补全,依据分割边界重建油茶单株树冠点云。
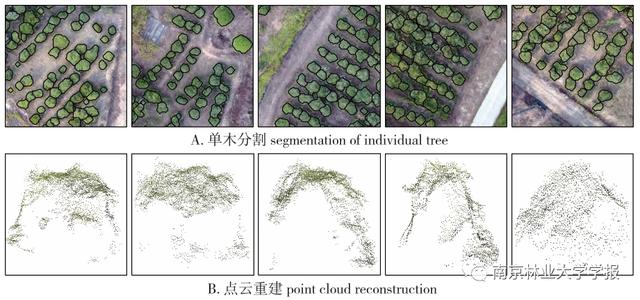
▲图 2 油茶单木分割及树冠点云重建结果
3.2 不同方法提取油茶树冠体积
不规则三角网(triangulated irregular network ,TIN)具有高效、适用性强的优点,以TIN模拟树冠并计算体积,能够在最大限度维持冠形不变的基础上缩短构网的时间。而过滤三角网法(FT)将边长超过阈值的三角形视为空隙,按顺时针方向对三角网边界进行过滤,直到所有边长超过阈值的三角形被剔除。以这样的方式计算树冠体积,使得提取结果更接近树冠实际轮廓。利用4种插值方法模拟树冠轮廓,插值结果见图3。相对另外3种方法而言,NN法模拟的树冠表面被过渡平滑,出现树冠轮廓失真,因此可能导致树冠体积计算结果相比其他方法偏大,而Krigmy法、IDW法和FT法模拟的表面相似。
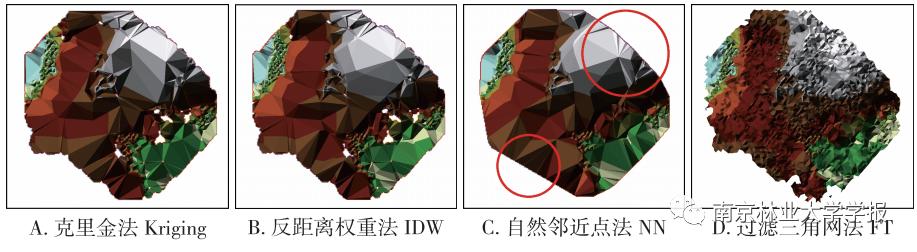
▲图 3 不同插值方法提取的树冠表面
体元法计算树冠体积在CAD中实现,设置体元边长为CAD格网最小边长5 cm,树冠体积即为立方体格网的体积之和,以该值作为体积实测值。通过三维分析分别计算4种插值方法获取的凸包体积,对比不同方法获取树冠体积的结果。Kriging法、IDW法,NN法和FT法提取树冠体积的平均相对误差分别为37.04% 、36.73% 、38.54% 、31.54%,图4为树冠体积提取值与实测值的对比。从总体来看,4种方法获取的体积相对误差均为30%~40% ,体积计算结果总体偏大。从不同插值方法来看,Kriging法的平均相对误差低于自然邻近点法,IDW法计算树冠体积的结果优于Kriging 法,FT法的平均相对误差最小。
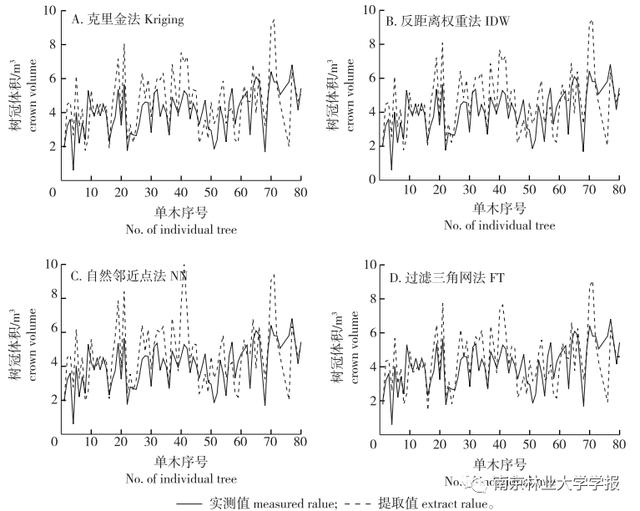
▲图 4 不同插值方法提取树冠体积结果对比
由图4可知,普通插值方法和FT方法获取的不同样木树冠体积大小与对应实测值的波动趋势一致,个别样木树冠体积计算值偏大或偏小造成平均相对误差变大,这是由于无人机倾斜摄影获取的点云为表层点云,树冠的部分细节被忽视,反观4种插值方法,FT能够最大限度地减小误差,因此选择使用FT方法提取的树冠体积与其他变量建立估测模型。
3.3 油茶树高和产量估测模型建模结果及精度验证
3.3.1 MLR变量筛选
经Pearson相关分析可知,在0.01水平上与树高显著相关的9个变量为V、HCHM、C、CEW、CSN、TCorrelation、R23、R123、R3相关系数分别为0.600、0.649、0.495、0.471、0.399、0.285、0.315、0.299、0.280,在0.05水平上与产量显著相关的变量共有14个。选择显著性水平在0.05以上的变量结合MLR估测树高(H),最终筛选的变量为HCHM、V,建立的多元线性回归模型方程为:
Y=0.318x1+ 0.072x2+1.201。 (8)
式中:Y表示树高(H); x1表示最大冠层高度值(HCHM); x2表示树冠体积(V)。
同样计算各变量与产量之间的Pearson相关系数矩阵,在0.01水平上与产量显著相关的4个变量为V、HCHM、TCorrelation、H,相关系数分别是0.333,0.287 ,0.294,0.420,在0.05水平上与产量显著相关的变量共有37个。同理,选择显著性水平在0.05以上的变量建立MLR估产模型最终筛选的变量为H、H5、Hiq、TCorrelation,建立的多元线性回归模型方程为:
Y=4.961x1+ 2.208 x2+4.248x3-22.238x4+11.150。 (9)
式中:Y表示产量;x1表示树高(H); x2表示累积高度百分位数(H5) ;x3表示高度变量(Hiq) ;x4表示相关性(TCorrelation)。
3.3.2 RF变量筛选
重要性用于评估变量对模型的贡献程度,重要性越高的变量与因变量的非线性关系越好,对预测的影响程度越大。重要性排序后,选择使模型误差达到最小的变量组合。树高、产量随机森林模型的相对均方根误差与估测变量个数之间的关系见图5,从图5可以看出,并不是所有的变量都在放入模型时误差最小,变量个数的增加可以降低估测误差,但随着变量的增加误差呈现出先减小再增大最后逐渐稳定的趋势。
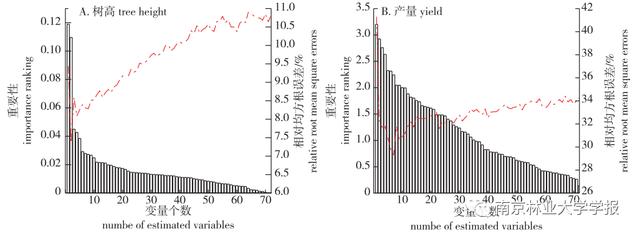
▲图 5 相对均方根误差和估测变量个数间的关系
依次将重要性低的变量剔除后,树高模型最终保留了2个自变量(V、HCHM),产量模型最终保留7个自变量(H、CWE、H5、Hiq、P70、D7、TCorrelation),图5表示变量的重要性排序。在两种变量筛选方式中,树高和产量保留的变量基本一致。产量的保留变量中, H 、H5、HIQ为树高变量,说明树高对产量有一定程度的影响;有研究发现小麦孕穗期的纹理特征与产量相关性可达到极显著水平,在本研究中,纹理特征同样与油茶产量显著相关。
3.3.3 油茶树高和产量估测结果
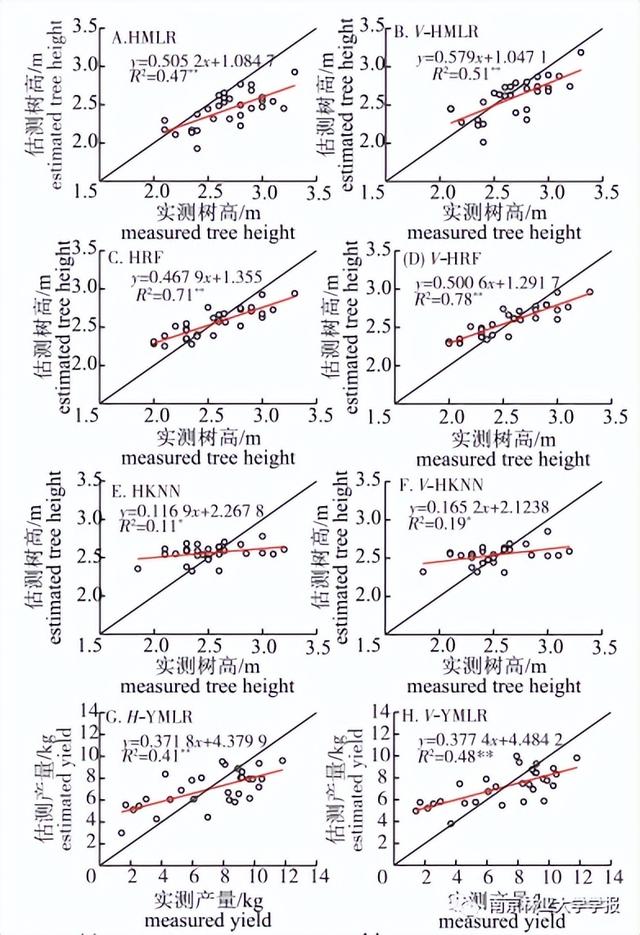
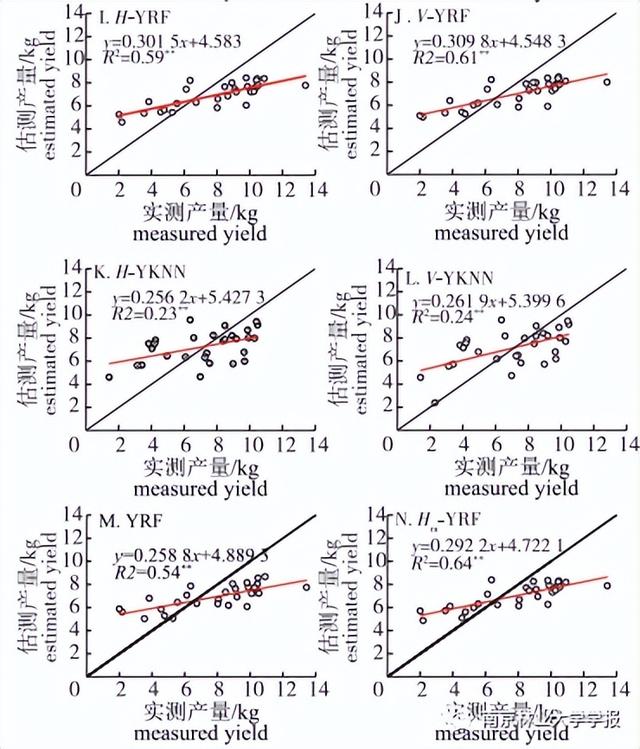
分别利用3种模型估测的树高、产量与实测树高、产量进行一元线性回归,树高基础多元线性回归模型(HMLR)、树高基础随机森林模型( HRF) 、树高基础K最邻近模型(HKNN)、产量基础多元线性回归模型(H-YMLR)、产量基础随机森林模型(H-YRF)和产量基础K最邻近模型(H-YKNN)及分别表示向基础模型中加入树冠体积(V-HMLR、V-HRF、V-HKNN 、V-YMLR、V-YRF、V-YKNN)的建模结果见图6。
由实测树高与估测树高的线性回归图可知:随机森林模型的树高估测值与实测值之间的相关性明显优于K最邻近模型和多元线性回归模型,K最邻近模型的估测树高与实测树高在0.05水平上显著相关,而多元线性回归模型和随机森林模型的估测树高与实测树高在0.01水平上显著相关。
由实测产量与估测产量的线性回归图可知:多元线性回归模型和随机森林模型的效果较理想,产量估测值与实测值之间具有较好的相关性,而K最邻近模型效果不如另外两种,但3种模型的估测产量与实测产量均在0.01水平上显著相关。
树高和产量的建模结果见表2,加入树冠体积的树高多元线性回归模型(V-HMLR,R2=0.51 ,RMSE为0.23 m, RRMSE为8.44%)、随机森林模型(V-HRF ,R2=0.78, RMSE为0.19 m, RRMSE为7.41%),K最邻近模型精度(V-HKNN , R2= 0.19,RMSE为0.28 m , RRMSE为11.03%)均优于基础模型精度,其相对均方根误差分别减小了3.77%、0.78% 、0.64% ,对比3种模型,随机森林的估测效果最好,多元线性回归优于K最邻近。
将树冠体积作为特征变量参与建模后,产量多元线性回归模型(V-YMLR,R2=0.48,RMSE为2.39kg, RRMSE为30.02%)、随机森林模型(V-YRF ,R2=0.61,RMSE为2.29 kg, RRMSE为28.96%) ,K最邻近模型精度(V-YKNN,R2=0.24,RMSE为2.43kg, RRMSE为 30.67%)相比基础模型均有一定程度提升,其相对均方根误差分别减小了1.32% 、0.34%、0.16% ,在3种估测模型中,随机森林的估测效果优于多元线性回归,K最邻近最差。
▲图 6 树高、产量的估测值与实测值散点图
注:*P<0.05,**P<0.01。
▼表 2 树高和产量的估测模型精度
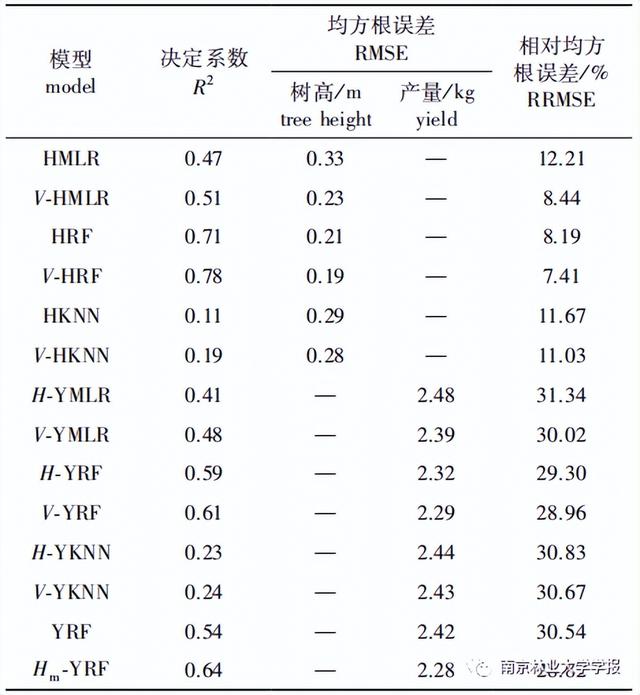
为了对比估测树高(H)与实测树高(Hm)建模结果的差异,分析H对建模的有效性,分别利用随机森林筛选的变量集、Hm结合变量集构建估产模型(YRF、Hm-YRF)见图6,建模精度见表2。引人Hm的产量模型精度(Hm-YRF ,R2= 0.64,RMSE为2.28 kg, RRMSE为28.82%)与利用H估产的精度相比有提升,但仅提升了0.14% ,而不考虑引人H或Hm的估产模型精度(YRF , R2= 0.54,RMSE为2.42 kg , RRMSE为30.54%)相比其他模型有所下降。
4结论
结合树冠体积和树高参与建模可有效提高油茶产量估测精度,研究结果可为区域范围内利用无人机遥感技术开展油茶树高和产量调查提供参考。

关注我们,更多精彩

好了,这篇文章的内容发货联盟就和大家分享到这里,如果大家网络推广引流创业感兴趣,可以添加微信:80709525 备注:发货联盟引流学习; 我拉你进直播课程学习群,每周135晚上都是有实战干货的推广引流技术课程免费分享!